本章内容:
- 根据一个或多个键拆分pandas对象;
- 计算分数摘要统计;
- 对DataFrame的列应用各种函数;
- 应用组内转换或运算;
- 计算透视表或交叉表;
- 执行分位数分析等;
1 GroupBy技术
分组聚合演示:
In [4]: df = DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','o
...: ne'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
In [5]: df
Out[5]:
data1 data2 key1 key2
0 -0.187814 -0.224238 a one
1 -1.363033 0.087923 a two
2 0.624801 -0.132735 b one
3 0.643536 0.335998 b two
4 -1.318154 0.208845 a one
In [6]: grouped=df['data1'].groupby(df['key1']) # 将data1数据按照key1进行分组
In [7]: grouped
Out[7]: <pandas.core.groupby.SeriesGroupBy object at 0x0000000007D7FEF0>
In [8]: grouped.mean() # 求各分组的平均值
Out[8]:
key1
a -0.956334
b 0.634169
Name: data1, dtype: float64
In [9]: means = df['data1'].groupby([df['key1'],df['key2']]).mean()
In [10]: means #分层索引 进行分组
Out[10]:
key1 key2
a one -0.752984
two -1.363033
b one 0.624801
two 0.643536
Name: data1, dtype: float64
In [11]: means.unstack() # 解stack
Out[11]:
key2 one two
key1
a -0.752984 -1.363033
b 0.624801 0.643536
# 数据和分组是Series,其实也可以是其他任意的数组,arange
In [12]: df.groupby('key1').mean()
Out[12]: # key2不是数值列,因此属于“麻烦列”,不能用于计算mean,所以去除掉了。
data1 data2
key1
a -0.956334 0.024177
b 0.634169 0.101632
In [13]: df.groupby(['key1','key2']).mean()
Out[13]:
data1 data2
key1 key2
a one -0.752984 -0.007696
two -1.363033 0.087923
b one 0.624801 -0.132735
two 0.643536 0.335998
# 返回分组后,每组的数量
In [17]: df.groupby(['key1','key2']).size()
Out[17]:
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
1.1 对分组进行迭代
对groupby对象,可以进行迭代。
# name: set(key1)中的值,进行循环组名
# group:每个name对应的df的子集
In [18]: for name,group in df.groupby('key1'):
...: print(name)
...: print(group)
...:
a
data1 data2 key1 key2
0 -0.187814 -0.224238 a one
1 -1.363033 0.087923 a two
4 -1.318154 0.208845 a one
b
data1 data2 key1 key2
2 0.624801 -0.132735 b one
3 0.643536 0.335998 b two
# 使用(k1,k2)元组来循环分组的组名
In [20]: for (k1,k2),group in df.groupby(['key1','key2']):
...: print(k1,k2)
...: print(group)
...:
('a', 'one')
data1 data2 key1 key2
0 -0.187814 -0.224238 a one
4 -1.318154 0.208845 a one
('a', 'two')
data1 data2 key1 key2
1 -1.363033 0.087923 a two
('b', 'one')
data1 data2 key1 key2
2 0.624801 -0.132735 b one
('b', 'two')
data1 data2 key1 key2
3 0.643536 0.335998 b two
# 可以进行字典、列表操作
In [21]: dict(list(df.groupby('key1')))['b']
Out[21]:
data1 data2 key1 key2
2 0.624801 -0.132735 b one
3 0.643536 0.335998 b two
In [24]: df.dtypes
Out[24]:
data1 float64
data2 float64
key1 object
key2 object
dtype: object
# 默认使用axis=0进行分类,也可以按照列进行分类
In [25]: df.groupby(df.dtypes,axis=1)
Out[25]: <pandas.core.groupby.DataFrameGroupBy object at 0x0000000007F024A8>
In [26]: grouped = df.groupby(df.dtypes,axis=1)
In [27]: dict(list(grouped))
Out[27]:
{dtype('float64'): data1 data2
0 -0.187814 -0.224238
1 -1.363033 0.087923
2 0.624801 -0.132735
3 0.643536 0.335998
4 -1.318154 0.208845, dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one}
1.2 选取一个或一组列
In [28]: df.groupby('key1')['data1'] # 等价于[31]
Out[28]: <pandas.core.groupby.SeriesGroupBy object at 0x0000000007F02550>
In [29]: df.groupby('key1')[['data1','data2']] # 等价于[33]
Out[29]: <pandas.core.groupby.DataFrameGroupBy object at 0x0000000007E448D0
In [31]: df['data1'].groupby(df['key1'])
Out[31]: <pandas.core.groupby.SeriesGroupBy object at 0x0000000007F02198>
In [33]: df[['data1','data2']].groupby(df['key1'])
Out[33]: <pandas.core.groupby.DataFrameGroupBy object at 0x0000000007FE8EF0>
1.3 通过字典或Series进行分组
In [35]: people = DataFrame(np.random.randn(5,5),columns=list('abcde'),index=['
...: Joe','Steve','Wes','Jim','Travis'])
In [36]: people.ix[2:3,'b':'c'] = np.nan
In [37]: people
Out[37]:
a b c d e
Joe 0.231921 -0.185109 -1.103585 0.919247 0.827190
Steve 0.336541 -0.358981 -0.897516 0.772835 -1.774432
Wes -0.069938 NaN NaN 0.268681 -1.199919
Jim 1.324175 -0.968378 -2.376905 -0.222219 -2.366535
Travis 0.815229 -1.139785 -2.045500 -1.576867 -0.578046
# 用字典进行分组
In [38]: mapping = {'a':'red','b':'green','c':'red','d':'red','e':'green'}
In [39]: people.groupby(mapping,axis=1)
Out[39]: <pandas.core.groupby.DataFrameGroupBy object at 0x000000000803A048>
In [40]: people.groupby(mapping,axis=1).sum() # 将列进行重新映射
Out[40]:
green red
Joe 0.642080 0.047583
Steve -2.133413 0.211860
Wes -1.199919 0.198743
Jim -3.334913 -1.274948
Travis -1.717832 -2.807137
# 同样的,也可以使用Series进行分组
In [44]: mapping = Series(mapping)
In [45]: people.groupby(mapping,axis=1).count()
Out[45]:
green red
Joe 2 3
Steve 2 3
Wes 1 2
Jim 2 3
Travis 2 3
1.4 通过函数进行分组
groupby也可以传入函数,分别在索引值上执行一便,并将返回值作为新的分组名称。
In [46]: people
Out[46]:
a b c d e
Joe 0.231921 -0.185109 -1.103585 0.919247 0.827190
Steve 0.336541 -0.358981 -0.897516 0.772835 -1.774432
Wes -0.069938 NaN NaN 0.268681 -1.199919
Jim 1.324175 -0.968378 -2.376905 -0.222219 -2.366535
Travis 0.815229 -1.139785 -2.045500 -1.576867 -0.578046
# 按照人名长度进行分类,并计算对应列的和
In [47]: people.groupby(len).sum()
Out[47]:
a b c d e
3 1.486159 -1.153487 -3.480490 0.965709 -2.739264
5 0.336541 -0.358981 -0.897516 0.772835 -1.774432
6 0.815229 -1.139785 -2.045500 -1.576867 -0.578046
In [48]: key_list = ['one','one','one','two','two']
# 按照人名、keylist进行分组,并计算组中最小值
In [49]: people.groupby([len,key_list]).min()
Out[49]:
a b c d e
3 one -0.069938 -0.185109 -1.103585 0.268681 -1.199919
two 1.324175 -0.968378 -2.376905 -0.222219 -2.366535
5 one 0.336541 -0.358981 -0.897516 0.772835 -1.774432
6 two 0.815229 -1.139785 -2.045500 -1.576867 -0.578046
1.5 按照索引级别进行分组
In [51]: columns = pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],[1,3,5
...: ,1,3]],names=['cty','tenor'])
In [52]: hier_df = DataFrame(np.random.randn(4,5), columns=columns)
In [53]: hier_df
Out[53]:
cty US JP
tenor 1 3 5 1 3
0 -0.295106 1.021162 -0.233712 -0.708512 0.617306
1 0.404333 1.224998 -0.169200 0.939965 -1.030823
2 0.095957 0.617305 0.867929 1.774633 0.800739
3 1.433123 0.355095 -0.377080 -0.360470 0.690263
In [54]: hier_df.groupby(level='cty',axis=1).count() #按照级别cty进行分组
Out[54]:
cty JP US
0 2 3
1 2 3
2 2 3
3 2 3
2 数据聚合
从数组产生标量值的数据转化过程。
In [5]: df
Out[5]:
data1 data2 key1 key2
0 -1.809227 2.231607 a one
1 1.663738 -0.113191 a two
2 0.411805 -0.842909 b one
3 1.244803 -1.147212 b two
4 1.014822 0.122223 a one
In [6]: grouped = df.groupby('key1')
In [7]: grouped['data1'].quantile(0.9) # 0.9分位数,
Out[7]:
key1
a 1.533955
b 1.161503
Name: data1, dtype: float64
# 还有之前的sum,mean等。
# 也能传入自定义函数
In [5]: def peak_to_peak(arr):
...: return arr.max()-arr.min()
In [9]: grouped.agg(peak_to_peak)
Out[9]:
data1 data2
key1
a 3.472965 2.344798
b 0.832998 0.304303
In [10]: grouped.describe()
Out[10]:
data1 data2
key1
a count 3.000000 3.000000
mean 0.289777 0.746880
std 1.846521 1.291188
min -1.809227 -0.113191
25% -0.397203 0.004516
50% 1.014822 0.122223
75% 1.339280 1.176915
max 1.663738 2.231607
b count 2.000000 2.000000
mean 0.828304 -0.995061
std 0.589018 0.215175
min 0.411805 -1.147212
25% 0.620055 -1.071137
50% 0.828304 -0.995061
75% 1.036554 -0.918985
max 1.244803 -0.842909
经过groupby优化过的方法

2.1 面向列的多函数应用
针对列的聚合运算其实就是agg或者使用mean、sum等方法。如果需要多个聚合函数同时作用:
# 以列表的形式传入agg,元素为函数名称或函数对象。
In [9]: df.groupby('key1').agg(['mean', peak_to_peak])
Out[9]:
data1 data2
mean peak_to_peak mean peak_to_peak
key1
a 0.143435 2.047937 0.934671 1.279921
b 0.037396 1.884494 -1.087873 1.018864
# 还可以定义列名 (列名,函数名)
In [10]: df.groupby('key1').agg([('Mean','mean'),('bar',np.std)])
Out[10]:
data1 data2
Mean bar Mean bar
key1
a 0.143435 1.125854 0.934671 0.673188
b 0.037396 1.332538 -1.087873 0.720446
# 对不同的列,应用不同的函数,使用字典
In [11]: func_dict = {'data1':'mean','data2':np.std}
In [12]: df.groupby('key1').agg(func_dict)
Out[12]:
data1 data2
key1
a 0.143435 0.673188
b 0.037396 0.720446
2.2 以无索引的形式返回聚合数据
在groupby中默认会以唯一的分组键作为索引,如果参数中传入“as_index=False”即可禁止索引。
In [13]: df.groupby('key1',as_index=False).mean()
Out[13]:
key1 data1 data2
0 a 0.143435 0.934671
1 b 0.037396 -1.087873
# 相同的结果
In [17]: df.groupby('key1').mean().reset_index()
Out[17]:
key1 data1 data2
0 a 0.143435 0.934671
1 b 0.037396 -1.087873
3 分组级运算和转换
聚合只是分组运算和转换的一个特例,他能够接受的是将一维数组简化为标量的函数。 本节的transform和apply函数能够执行更多的分组运算
In [19]: df
Out[19]:
data1 data2 key1 key2
0 0.897195 0.693473 a one
1 0.683851 1.695230 a two
2 -0.904851 -0.578441 b one
3 0.979643 -1.597305 b two
4 -1.150742 0.415309 a one
In [22]: k1_mean = df.groupby('key1').mean().add_prefix('mean_')
In [25]: df.merge(k1_mean,left_on='key1',right_index=True)
Out[25]:
data1 data2 key1 key2 mean_data1 mean_data2
0 0.897195 0.693473 a one 0.143435 0.934671
1 0.683851 1.695230 a two 0.143435 0.934671
4 -1.150742 0.415309 a one 0.143435 0.934671
2 -0.904851 -0.578441 b one 0.037396 -1.087873
3 0.979643 -1.597305 b two 0.037396 -1.087873
# 这样稍显麻烦
我们使用 transform 再来试一试。
In [12]: key = ['one','two','one','two','one']
In [13]: people
Out[13]:
a b c d e
Joe -0.632221 0.074549 -0.964887 -2.144542 1.787703
Steve -0.442427 0.925263 0.646603 0.719694 -0.208777
Wes -0.019415 0.032652 -0.475912 0.490444 -0.305742
Jim 0.214406 -0.263113 -1.867597 1.762480 1.024320
Travis 0.348362 -0.650411 -1.660043 -0.332139 -0.669246
In [14]: people.groupby(key).mean() # 求用key分类后的平均值
Out[14]:
a b c d e
one -0.101091 -0.181070 -1.033614 -0.662079 0.270905
two -0.114010 0.331075 -0.610497 1.241087 0.407772
In [15]: people.groupby(key).transform(np.mean) # 将通过key计算出来的平均值,赋值回去
Out[15]:
a b c d e
Joe -0.101091 -0.181070 -1.033614 -0.662079 0.270905
Steve -0.114010 0.331075 -0.610497 1.241087 0.407772
Wes -0.101091 -0.181070 -1.033614 -0.662079 0.270905
Jim -0.114010 0.331075 -0.610497 1.241087 0.407772
Travis -0.101091 -0.181070 -1.033614 -0.662079 0.270905
In [16]: def demean(arr):
...: return arr-arr.mean()
...:
# transform 会将传入的函数应用到各个分组中,并将结果放到适当的位置上去。
#
In [17]: demeaned = people.groupby(key).transform(demean)
In [18]: demeaned
Out[18]:
a b c d e
Joe -0.531130 0.255619 0.068727 -1.482463 1.516798
Steve -0.328417 0.594188 1.257100 -0.521393 -0.616549
Wes 0.081676 0.213722 0.557702 1.152523 -0.576647
Jim 0.328417 -0.594188 -1.257100 0.521393 0.616549
Travis 0.449453 -0.469341 -0.626429 0.329940 -0.940151
In [19]: demeaned.groupby(key).mean()
Out[19]:
a b c d e
one 1.850372e-17 1.850372e-17 -1.110223e-16 -5.551115e-17 0.0
two 0.000000e+00 0.000000e+00 -1.110223e-16 0.000000e+00 0.0
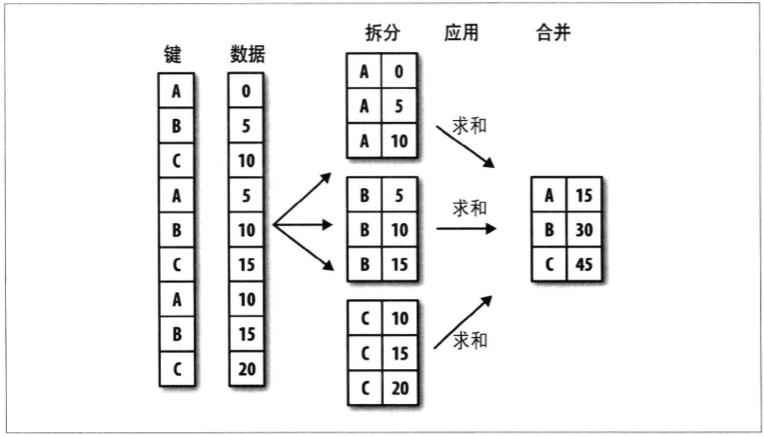
3.1 apply:一般性的“拆分-应用-合并”
transform与agg是一样的,要么产生一个可以广播的标量,要么产生一个相同大小的数组。 apply会将对象拆分成多个片段,然后对各个片段传入函数,最后尝试组合。 即“拆分-应用-合并”。
In [14]: tips = pd.read_csv('tips.csv')
In [15]: tips['tip_pct']=tips['tip']/tips['total_bill']
In [16]: tips
Out[16]:
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.059447
1 10.34 1.66 Male No Sun Dinner 3 0.160542
2 21.01 3.50 Male No Sun Dinner 3 0.166587
In [17]: def top(df, n=5, column = 'tip_pct'):
...: return df.sort_index(by=column)[-n:]
...:
In [18]: top(tips, n=6)
C:\Users\yangfl\Anaconda3\Scripts\ipython-script.py:2: FutureWarning: by argumen
t to sort_index is deprecated, pls use .sort_values(by=...)
import sys
Out[18]:
total_bill tip sex smoker day time size tip_pct
109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
232 11.61 3.39 Male No Sat Dinner 2 0.291990
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
In [17]: def top(df, n=5, column = 'tip_pct'):
...: return df.sort_index(by=column)[-n:]
...:
In [18]: top(tips, n=6)
C:\Users\yangfl\Anaconda3\Scripts\ipython-script.py:2: FutureWarning: by argumen
t to sort_index is deprecated, pls use .sort_values(by=...)
import sys
Out[18]:
total_bill tip sex smoker day time size tip_pct
109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
232 11.61 3.39 Male No Sat Dinner 2 0.291990
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
In [19]: tips.groupby('smoker').apply(top)
C:\Users\yangfl\Anaconda3\Scripts\ipython-script.py:2: FutureWarning: by argumen
t to sort_index is deprecated, pls use .sort_values(by=...)
import sys
Out[19]:
total_bill tip sex smoker day time size tip_pct
smoker
No 88 24.71 5.85 Male No Thur Lunch 2 0.236746
185 20.69 5.00 Male No Sun Dinner 5 0.241663
51 10.29 2.60 Female No Sun Dinner 2 0.252672
149 7.51 2.00 Male No Thur Lunch 2 0.266312
232 11.61 3.39 Male No Sat Dinner 2 0.291990
Yes 109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
In [20]: result = tips.groupby('smoker')['tip_pct'].describe()
In [21]: result
Out[21]:
smoker
No count 151.000000
mean 0.159328
std 0.039910
min 0.056797
25% 0.136906
50% 0.155625
75% 0.185014
max 0.291990
Yes count 93.000000
mean 0.163196
std 0.085119
min 0.035638
25% 0.106771
50% 0.153846
75% 0.195059
max 0.710345
Name: tip_pct, dtype: float64
禁止分组键
In [22]: tips.groupby('smoker', group_keys=False).apply(top)
C:\Users\yangfl\Anaconda3\Scripts\ipython-script.py:2: FutureWarning: by argumen
t to sort_index is deprecated, pls use .sort_values(by=...)
import sys
Out[22]:
total_bill tip sex smoker day time size tip_pct
88 24.71 5.85 Male No Thur Lunch 2 0.236746
185 20.69 5.00 Male No Sun Dinner 5 0.241663
51 10.29 2.60 Female No Sun Dinner 2 0.252672
149 7.51 2.00 Male No Thur Lunch 2 0.266312
232 11.61 3.39 Male No Sat Dinner 2 0.291990
109 14.31 4.00 Female Yes Sat Dinner 2 0.279525
183 23.17 6.50 Male Yes Sun Dinner 4 0.280535
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
3.2 分位数和桶分析
分位数
In [23]: frame = DataFrame({'data1':np.random.randn(1000),'data2':np.random.ran
...: dn(1000)})
In [24]: factor = pd.cut(frame.data1, 4) #分成四份
In [25]: factor[:5]
Out[25]:
0 (-0.122, 1.486]
1 (-1.73, -0.122]
2 (1.486, 3.0932]
3 (-1.73, -0.122]
4 (-0.122, 1.486]
Name: data1, dtype: category
Categories (4, object): [(-3.344, -1.73] < (-1.73, -0.122] < (-0.122, 1.486] < (
1.486, 3.0932]]
In [26]: def get_stats(group):
...: return {"min":group.min(),
...: 'max':group.max(),
...: 'count':group.count(),
...: 'mean':group.mean()}
...:
In [27]: grouped = frame.data2.groupby(factor)
In [28]: grouped.apply(get_stats).unstack()
Out[28]:
count max mean min
data1
(-3.344, -1.73] 38.0 2.219138 0.068483 -2.613319
(-1.73, -0.122] 421.0 3.024953 -0.043523 -2.733123
(-0.122, 1.486] 472.0 3.882440 -0.023289 -4.073087
(1.486, 3.0932] 69.0 2.520630 0.067271 -2.593762
桶分析
In [29]: grouping = pd.qcut(frame.data1, 10, labels=False)
In [30]: grouped= frame.data2.groupby(grouping)
In [31]: grouped.apply(get_stats).unstack()
Out[31]:
count max mean min
data1
0 100.0 2.219138 -0.140476 -2.613319
1 100.0 2.877679 0.047305 -2.483696
2 100.0 2.716929 -0.043014 -2.446612
3 100.0 2.387355 -0.080337 -2.733123
4 100.0 3.024953 0.031980 -2.157749
5 100.0 2.617329 0.011424 -2.048438
6 100.0 2.362811 -0.074931 -2.942770
7 100.0 3.882440 0.024096 -3.038111
8 100.0 2.587888 -0.014792 -4.073087
9 100.0 2.520630 0.018031 -2.613203
3.3 示例:用特定于分组的值填充缺失值
In [32]: s = Series(np.random.randn(6))
In [33]: s[::2] = np.nan
In [34]: s
Out[34]:
0 NaN
1 0.818362
2 NaN
3 0.624027
4 NaN
5 -1.260203
dtype: float64
In [35]: s.fillna(s.mean()) # 使用平均值填充空值
Out[35]:
0 0.060729
1 0.818362
2 0.060729
3 0.624027
4 0.060729
5 -1.260203
dtype: float64
3.4 示例:随机采样和排列
一副扑克牌:
In [36]: suits = ['H','S','C','D'] # 四个花色
In [42]: card_val = (list(range(1,11))+[10]*3) * 4 # 21点
# A ~ K
In [44]: base_names = ['A'] + list(range(2,11)) + ['J','Q','K']
In [45]: cards =[]
In [46]: for suit in suits:
...: cards.extend(str(num)+suit for num in base_names)
...:
# 做一个Series
In [47]: deck = Series(card_val, index=cards)
In [48]: deck
Out[48]:
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
...
随机抽出5张牌
In [49]: def draw(deck,n=5):
...: return deck.take(np.random.permutation(len(deck))[:n])
...:
# np.random.permutation 随机排序
In [50]: draw(deck) # 随机抽出5张牌
Out[50]:
7C 7
2D 2
10D 10
2H 2
AD 1
dtype: int64
随机每种花色抽取两张牌
In [51]: get_suit = lambda card:card[-1]
In [52]: deck.groupby(get_suit).apply(draw, 2)
Out[52]:
C 2C 2
9C 9
D 8D 8
6D 6
H AH 1
10H 10
S 3S 3
6S 6
dtype: int64
3.5 示例:分组加权平均数和相关系数
In [54]: df = DataFrame({'category':list('aaaabbbb'),
...: 'data':np.random.randn(8),
...: 'weights':np.random.rand(8)})
In [55]: df
Out[55]:
category data weights
0 a -0.239087 0.172904
1 a -0.615509 0.511186
2 a 1.015113 0.778079
3 a -0.726262 0.284090
4 b 0.443518 0.189707
5 b 1.025131 0.764808
6 b -1.725867 0.108514
7 b 0.613947 0.696840
In [56]: grouped = df.groupby('category') # 分组
# 加权平均值
In [57]: get_wavg = lambda g: np.average(g['data'],weights=g['weights'])
In [58]: grouped.apply(get_wavg)
Out[58]:
category
a 0.130299
b 0.629996
dtype: float64
4 透视表和交叉表
4.1 透视表
透视表(pivot table): 根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个 矩形区域中。
- DataFrame表有一个pivot_table方法,还有一个顶级的pandas.pivot_table
- pivot_table还有一个分项小计选项,margins
In [32]: tips.pivot_table(index=['sex','smoker'])
Out[32]:
size tip tip_pct total_bill
sex smoker
Female No 2.592593 2.773519 0.156921 18.105185
Yes 2.242424 2.931515 0.182150 17.977879
Male No 2.711340 3.113402 0.160669 19.791237
Yes 2.500000 3.051167 0.152771 22.284500
In [33]: tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns='smoker
...: ')
Out[33]:
tip_pct size
smoker No Yes No Yes
sex day
Female Fri 0.165296 0.209129 2.500000 2.000000
Sat 0.147993 0.163817 2.307692 2.200000
Sun 0.165710 0.237075 3.071429 2.500000
Thur 0.155971 0.163073 2.480000 2.428571
Male Fri 0.138005 0.144730 2.000000 2.125000
Sat 0.162132 0.139067 2.656250 2.629630
Sun 0.158291 0.173964 2.883721 2.600000
Thur 0.165706 0.164417 2.500000 2.300000
# 增加分类汇总,margins=True
In [34]: tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns='smoker
...: ',margins=True)
Out[34]:
tip_pct size
smoker No Yes All No Yes All
sex day
Female Fri 0.165296 0.209129 0.199388 2.500000 2.000000 2.111111
Sat 0.147993 0.163817 0.156470 2.307692 2.200000 2.250000
Sun 0.165710 0.237075 0.181569 3.071429 2.500000 2.944444
Thur 0.155971 0.163073 0.157525 2.480000 2.428571 2.468750
Male Fri 0.138005 0.144730 0.143385 2.000000 2.125000 2.100000
Sat 0.162132 0.139067 0.151577 2.656250 2.629630 2.644068
Sun 0.158291 0.173964 0.162344 2.883721 2.600000 2.810345
Thur 0.165706 0.164417 0.165276 2.500000 2.300000 2.433333
All 0.159328 0.163196 0.160803 2.668874 2.408602 2.569672
# 可以使用aggfunc传入其他聚合函数
In [37]: tips.pivot_table(['tip_pct','size'],index=['sex','smoker'],columns='day',aggfunc=len, margins=True)
Out[37]:
tip_pct size
day Fri Sat Sun Thur All Fri Sat Sun Thur All
sex smoker
Female No 2.0 13.0 14.0 25.0 54.0 2.0 13.0 14.0 25.0 54.0
Yes 7.0 15.0 4.0 7.0 33.0 7.0 15.0 4.0 7.0 33.0
Male No 2.0 32.0 43.0 20.0 97.0 2.0 32.0 43.0 20.0 97.0
Yes 8.0 27.0 15.0 10.0 60.0 8.0 27.0 15.0 10.0 60.0
All 19.0 87.0 76.0 62.0 244.0 19.0 87.0 76.0 62.0 244.0
pivot_table参数:

4.2 交叉表
交叉表示一种计算分组频率的特殊透视表,
In [39]: tips[:5]
Out[39]:
total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.059447
1 10.34 1.66 Male No Sun Dinner 3 0.160542
2 21.01 3.50 Male No Sun Dinner 3 0.166587
3 23.68 3.31 Male No Sun Dinner 2 0.139780
4 24.59 3.61 Female No Sun Dinner 4 0.146808
In [40]:
In [40]: pd.crosstab([tips.time, tips.day],tips.smoker, margins=True)
Out[40]:
smoker No Yes All
time day
Dinner Fri 3 9 12
Sat 45 42 87
Sun 57 19 76
Thur 1 0 1
Lunch Fri 1 6 7
Thur 44 17 61
All 151 93 244