本章内容:
- 机器学习的简单概述;
- 机器学习的主要任务;
- 学习机器学习的主要原因;
- python语言优势
1. 何为机器学习
机器学习就是让我们利用计算机来彰显数据背后的真实意义;使用机器学习的地儿有人脸识别、手写数字 识别、垃圾邮件过滤、产品推荐等等。
机器学习就是把无序的数据转换成有用的信息。可以说,能够用于任何需要解释并操作数据的领域。
机器学习用到统计学知识,因为不是所有问题我们都能够建立十分精准的模型,需要得出结论就需要使用 统计学来实现。
机器学习将有助于我们穿越数据雾霾,从中抽取有用的信息。
2. 关键术语
专家系统
机器学习的目标就是创建某个方向的专家系统,替代这个方向的专家学者(理想)。
特征和实例
特征,也叫作属性。一个样本中实例的属性,说直白一点就是表中的列。表中的每一行就是一个实例。 每个属性对应的值可以是数值型、bool型、颜色等等。
分类
分类是机器学习的主要任务,区分实例的类别。
训练集
用于训练机器学习算法。既包含特征,也包含结果。直白一些就是一些人工已经经过分类的数据集,用于机器 来学习,让机器也具备分类能力的基础数据。
目标变量或类别
训练集中的已经分好的类别,叫做目标变量
知识表示
使用机器学习解决实际问题,并将它用规则集、或概率分布等方法表示出来。
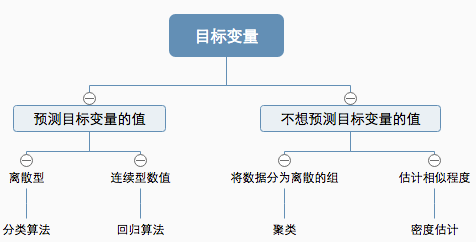
3. 机器学习的主要任务
监督学习
包括分类和回归。分类指将数据归类,回归如求数据点的最优拟合曲线。 监督学习必须知道要预测什么,及目标变量的分类信息是已经具备的。不能预测一个不知道的分类。
无监督学习
没有确切的分类信息。 将数据集合分成多个有相似特征的类,叫做聚类。 将描述数据统计值得过程称为密度估计。
无监督学习可以将数据特征进行降维,更直观的展示数据。
总结一下
监督学习:
- k邻近算法
- 朴素贝叶斯算法
- 支持向量机
- 决策树
- 。。。
无监督学习:
- k均值
- 最大期望算法
- 。。。
4. 如何选择合适的算法
使用算法的目的
根据目的,可以进行选择算法,举个例子:
需要收集和分析的数据是啥
数据了解的越充分,越容易建立符合需求的程序。需要了解数据的一下特征:
- 特征值是离散的还是连续的?
- 是否含有缺失值?
- 是否有异常值?
- 某个特征值发生的频率如何?
总结
一般情况下,只能缩小算法的选择范围,不存在最好的算法。 发现最好算法的关键步骤就是反复试错的迭代过程。
5. 开发机器学习应用程序的步骤
- 收集数据
- 准备输入数据:将数据转换成算法需要的数据;
- 分析输入数据:主要是通过人工方式查看数据是否存在明显的问题,可以使用二维或三维图形展示工具查看
- 训练算法:使用训练集对算法进行训练,无监督学习算法无本步骤
- 测试算法:用于检验算法的可用性
- 使用算法:执行算法
6. python相关
略。