1.1 语言计算:文本和单词
NLTK入门
In [1]: import nltk
In [10]: nltk.download() # 下载书中所需数据
In [49]: from nltk import book
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
In [50]: book.text1
Out[50]: <Text: Moby Dick by Herman Melville 1851>
In [51]: book.text2
Out[51]: <Text: Sense and Sensibility by Jane Austen 1811>
搜索文本
# 精确匹配单词
In [52]: book.text1.concordance("monstrous")
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
# 模糊匹配上下文
In [53]: book.text1.similar("monstrous")
imperial subtly impalpable pitiable curious abundant perilous
trustworthy untoward singular lamentable few determined maddens
horrible tyrannical lazy mystifying christian exasperate
In [54]: book.text2.similar("monstrous")
very exceedingly so heartily a great good amazingly as sweet
remarkably extremely vast
In [55]: book.text2.common_contexts(["monstrous","very"])
a_pretty is_pretty a_lucky am_glad be_glad
# 分散作图
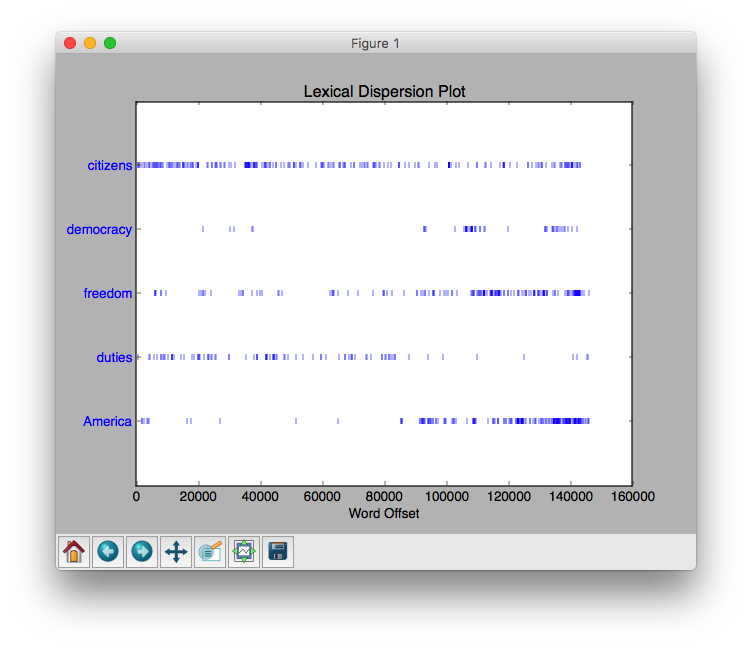
In [56]: book.text4.dispersion_plot(["citizens","democracy","freedom","duties","
...: America"])
计数词汇
In [5]: len(book.text3) # 计算所有词数
Out[5]: 44764
In [6]: len(sorted(set(book.text3))) # 去重
Out[6]: 2789
In [7]: from __future__ import division
In [9]: len(book.text3)/len(set(book.text3)) # 每个词平均出现16次
Out[9]: 16.050197203298673
In [10]: book.text3.count('smote')
Out[10]: 5
In [11]: 100 * book.text4.count("a")/len(book.text4) # a出现的比例
Out[11]: 1.4643016433938312
1.2 将文本当做词链表
链表(list)
# 相加
In [17]: book.sent3 + book.sent1
Out[17]:
['In',
'the',
'beginning',
'God',
'created',
'the',
'heaven',
'and',
'the',
'earth',
'.',
'Call',
'me',
'Ishmael',
'.']
#追加
In [18]: book.sent1.append('Some')
In [19]: book.sent1
Out[19]: ['Call', 'me', 'Ishmael', '.', 'Some']
索引列表
In [20]: book.text5[173] # 索引
Out[20]: u'to'
In [21]: book.text5[16715:16725] # 切片
Out[21]:
[u'U86',
u'thats',
u'why',
u'something',
u'like',
u'gamefly',
u'is',
u'so',
u'good',
u'because']
# list其他属性,略
变量
In [22]: vocab = set(book.text1)
In [23]: len(vocab)
Out[23]: 19317
字符串
In [24]: name = 'Monty'
In [25]: name*2
Out[25]: 'MontyMonty'
In [26]: name[2]
Out[26]: 'n'
In [27]: ''.join(['Monty','!'])
Out[27]: 'Monty!'
1.3 简单统计
频率分布
手动统计词频很费劲,不过计算机处理就更好一些。
# 统计词频
In [28]: fdist1 = book.FreqDist(book.text1)
In [29]: vocabulary1 = fdist1.keys()
In [30]: vocabulary1[:50]
Out[30]:
[u'funereal',
u'unscientific',
u'divinely',
u'foul',
u'four',
u'gag',
...
]
In [6]: fdist1.most_common()[:10]
Out[6]:
[(u',', 18713),
(u'the', 13721),
(u'.', 6862),
(u'of', 6536),
(u'and', 6024),
(u'a', 4569),
(u'to', 4542),
(u';', 4072),
(u'in', 3916),
(u'that', 2982)]
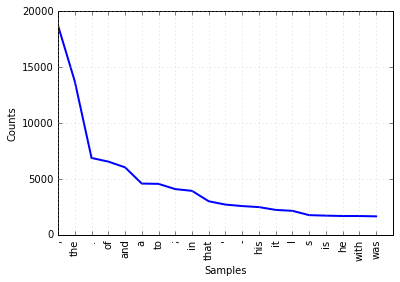
使用fdist1.plot(20)可以画出前20的词频统计图。
细粒度的选择词
取出词长度大于15的所有词。
In [3]: v = set(book.text1)
In [4]: long_words = [ w for w in v if len(w)>15 ]
In [5]: long_words
Out[5]:
[u'hermaphroditical',
u'subterraneousness',
u'uninterpenetratingly',
u'irresistibleness',
...]
取出出现次数超过7次的词。
In [7]: fdist5 = nltk.FreqDist(book.text5)
In [8]: sorted([w for w in set(book.text5) if fdist5[w]>7 ])
Out[8]:
[u'!',
u'!!',
u'!!!',
u'!!!!',
...
词语搭配和双联词
搭配是指经常在一起出现的常用词,一般不能随便使用近义词替换。
# 获取所有双连词
In [9]: nltk.bigrams(book.text1)
Out[9]: <generator object bigrams at 0x10f07e410>
# 获取最频繁的关联词
In [16]: book.text4.collocations()
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; Old
World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice;
God bless; every citizen; Indian tribes; public debt; one another;
foreign nations; political parties
计数其他东西
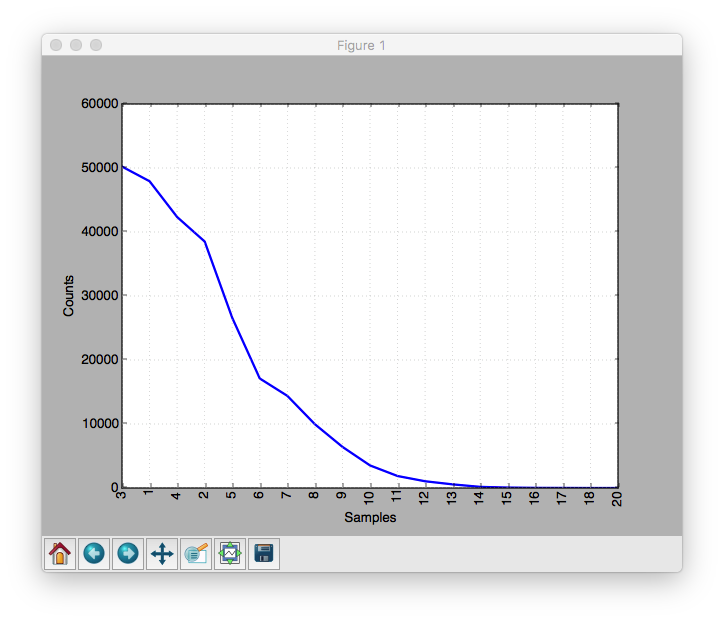
In [17]: fdist = nltk.FreqDist([len(w) for w in book.text1])
In [18]: fdist.keys()
Out[18]: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20]
In [19]: fdist.plot()
nltk频率分布的相关函数


1.4 python决策与控制
- 条件
- 嵌套
- 条件循环
1.5 自动理解自然语言
词意消歧
在词意消歧中,我们要算出特定上下文中的词被赋予的是哪个意思。
指代消解
一种更深刻的语言理解是解决“谁对谁做了什么”,即检测主语和动词的宾语。虽然你在 小学已经学会了这些,但它比你想象的更难。 要回答这个问题涉及到寻找代词 they 的先行词 thieves 或者 paintings。处理这个问题的 计算技术包括指代消解(anaphora resolution)——确定代词或名词短语指的是什么——和 语义角色标注(semantic role labeling)——确定名词短语如何与动词相关联(如施事,受 事,工具等)。
自动生成语言
如果我们能够解决自动语言理解等问题,我们将能够继续那些包含自动生成语言的任 务,如自动问答和机器翻译。
机器翻译
NLP的起源就是机器翻译(MT). 从新 闻和政府网站发布的两种或两种以上的语言文档中可以收集到大量的相似文本。给出一个德 文和英文双语的文档或者一个双语词典,我们就可以自动配对组成句子,这个过程叫做文本 对齐。
人机对话系统
在人工智能的历史,主要的智能测试是一个语言学测试,叫做图灵测试.
NLP 的局限性
自然语言处理研究的一个重要目标一直是使 用浅显但强大的技术代替无边无际的知识和推理能力,促进构建“ 语言理解”技术的艰巨任务 的不断取得进展。