0x03 内核线程之间的切换
1. 内核线程切换的例子
编写一个简单的用户程序例子,使用fork创建一个进程,父子两个进程不断在终端输出字符A和字符B,两个进程没有优先顺序,理论上来说无法判断输出的顺序。
// user/spin.c
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(){
char c;
int i = 0;
int pid = fork();
if( pid == 0){
c = 'A';
}else{
c = 'B';
}
while(1){
if(i % 10000000L == 0)
write(1,&c,1);
i++;
}
return 0;
}
运行效果如下:

那么输出A和输出B是两个进程,进程之间在不断地切换,同时也会在进程的内核线程之间进行切换。
2. 内核线程切换
从我们的例子来看,父进程和子进程都没有放弃CPU的操作,但是为啥还是能出现进程之间的切换?因为有 时钟中断的存在,过一小段时间,就会打断用户进程,进入内核空间。

开始进入GDB调式,在trap.c:80 设置一个断点,并执行。 which_dev 是devintr的返回值,是一个设备中断 类型的判断,这里暂时不纠结。 下面将执行 yield 主动放弃 CPU,这里将会发生进程的内核线程切换。
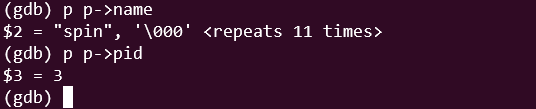
当前进程是 spin,pid=3,然后我们进入 yield 函数,看看发生了什么。 yiled 函数非常简单,修改当前进程 的状态并进入sched()函数。
sched函数也很简单,就是进行 swtch 切换内核线程,切换到 scheduler 线程。 另外,其他的部分要么是条件的判断,要么是设置中断相关内容。
其切换过程如下所示:
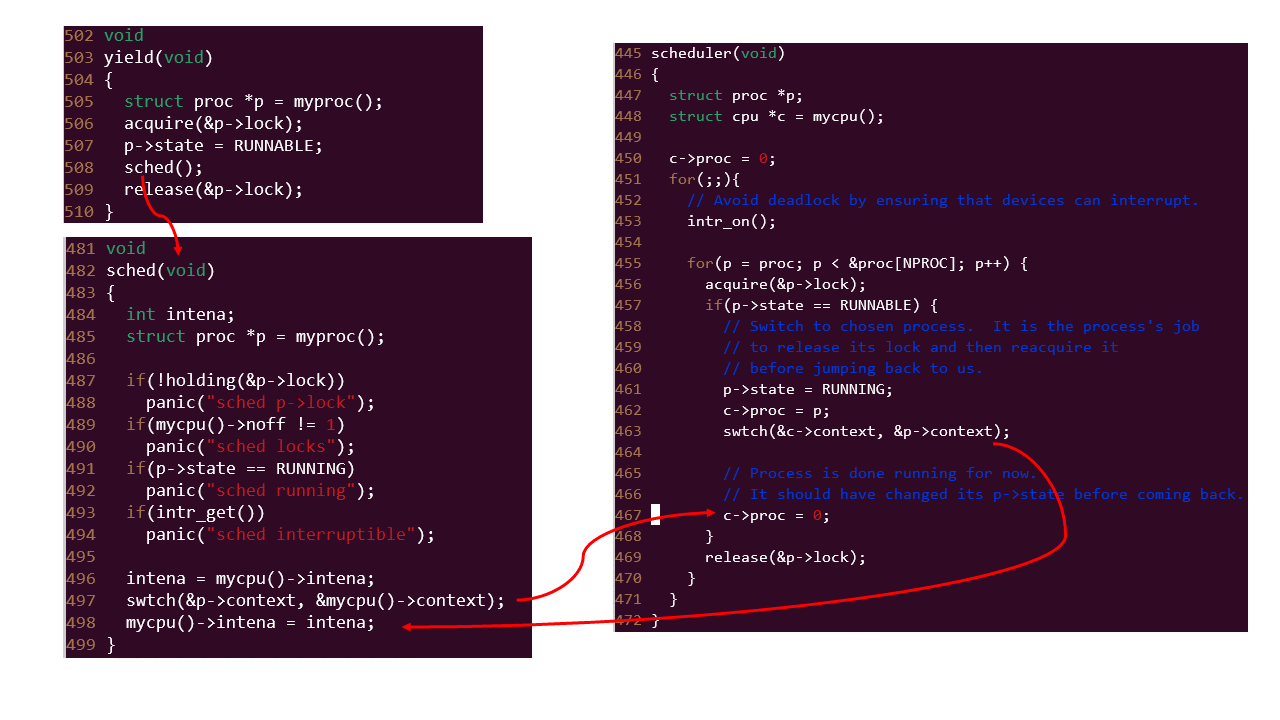
这段比较难以理解,为啥两个 swtch 之间会相互切换。 最主要是需要理解内核线程状态,这里定义是 strcut context,只要切换context,就可以切换线程。
- 内核线程的寄存器,s0-s11,callee保存的寄存器需要单独保存起来;
- 内核线程的栈,需要进行切换的,所以有必要切换sp寄存器;
- 内核线程使用的内存,共享的,所以不需要处理。
所以内核线程切换需要单独保存 sp,s0-s11,还有保存函数返回值的ra寄存器,保存到 struct context 中。 另外swtch函数(kernel/swtch.S)用来切换两个内核线程(swtch函数名,避免与C关键字switch冲突。), 将设计的14个寄存器保存到a0指定的context,恢复a1指定的context。
另外,关于切换过程中的进程锁(p->lock),可以看到 kernel/proc.h 中struct proc的定义,修改p->state 的时候需要持有进程锁。这点本身不难理解,以为有多个CPU在执行调度程序,我们如果修改了进程的状态,但是context还没有进行切换的话,就会出现混乱,这是我们不想出现问题,所以将这些过程用锁来保护起来。
但是,在切换线程的时候,加锁和解锁的过程可能有点特殊。一般情况下,都是那个线程加的锁,哪个线程来解锁,但 这里不是这样的。
- 假设pid=3进程执行到了yiled 函数中
加锁,调用sched(),然后切换到scheduler()中解锁。这个过程完成了,进程的状态完成从running切换到runnable状态; - 这是可能有别的cpu在执行scheduler()找到了pid=3这个进程,其过程是
加锁,修改state为running,swtch切换。这下一切换就会返回到pid=3进程之前运行的地方,也就是sched()函数,进而返回到yield(),然后进程解锁。然后进程返回用户空间,继续执行。
3. 过程演示
- yield 执行到sched,当前进程pid=3,已加锁。
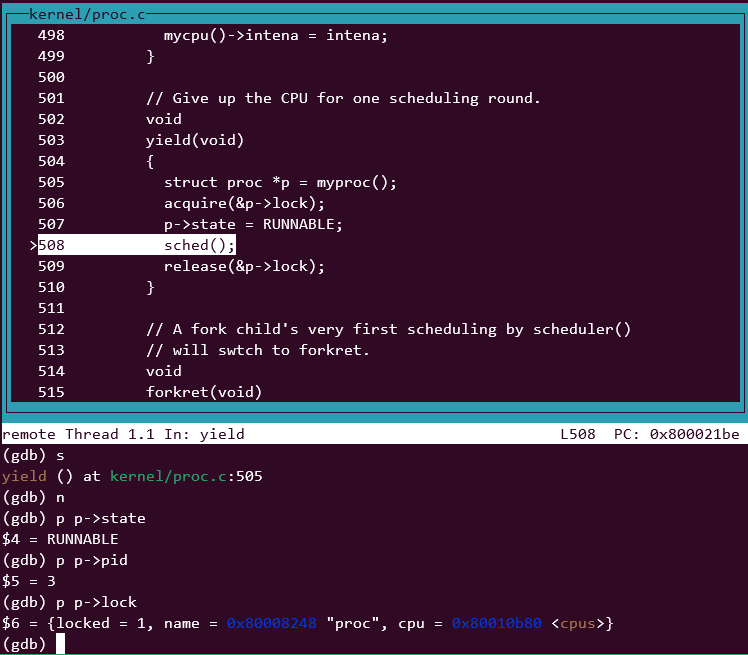
- sched 到 swtch, 切换到scheduler
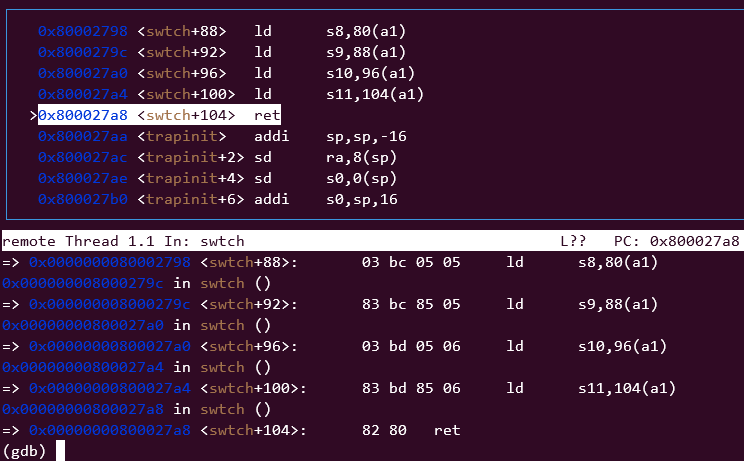
执行ret之后,因为ra发生了改变,直接切换到了scheduler
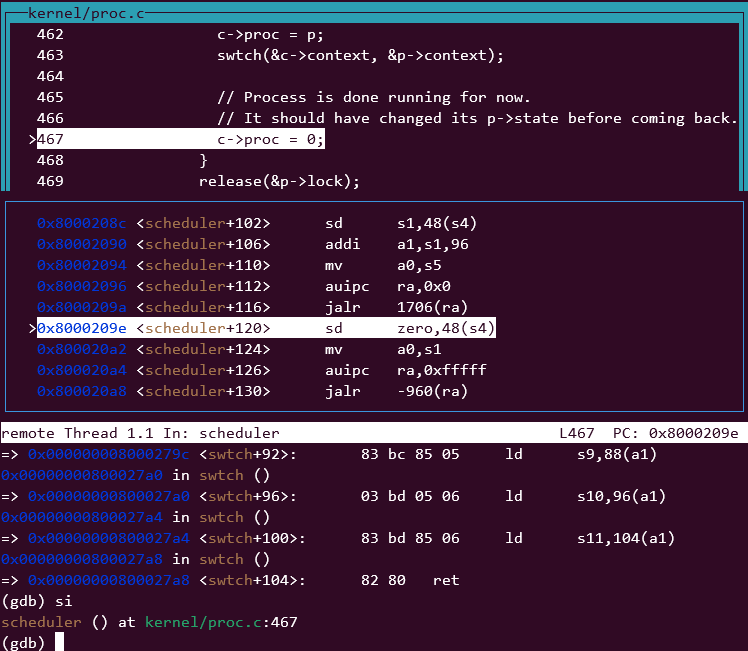
切换过来之后,看下当前的进程,pid=3,已加锁。
(gdb) p p->name
$10 = "spin", '\000' <repeats 11 times>
(gdb) p p->pid
$11 = 3
(gdb) p p->lock
$12 = {locked = 1, name = 0x80008248 "proc", cpu = 0x80010b80 <cpus>}
可能有疑惑: 为啥切换到scheduler线程之后,也是pid=3进程。 因为scheduler是先运行的,先从这个位置跳转到了用户进程,后续才有用户进程跳回来。
- 清除 c->proc 信息,并解锁。
- 继续运行scheduler(), 遍历proc[]数组,获得下一个可用的进程,并加锁。
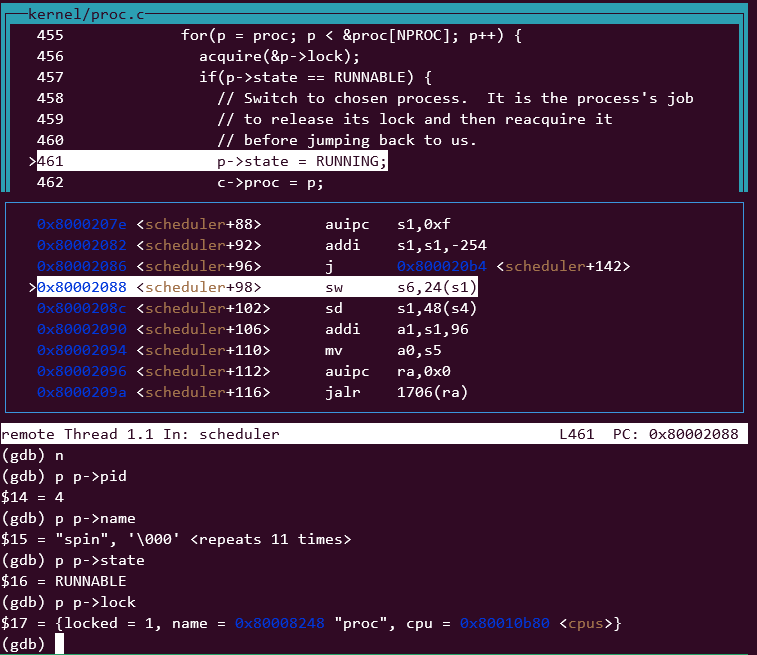
- 设置进程state,当前cpu的运行进程c->proc,然后swtch到选中的这个进程,这里是pid=4, 如果这个进程是刚被创建的,第一次执行,就会先跳转到 forkret
现在这个进程是加锁的状态,需要解锁再返回用户空间(usertrapret())开始执行新进程代码。
如果不是刚被创建的进程,已经执行过了,那么就会跳转到 sched() 并跳转到 yield(),这时候 已经切换为pid=4的进程,状态如下:

yield解锁该进程,通过usertrapret()返回用户空间,到sret时,看下返回到用户空间哪?
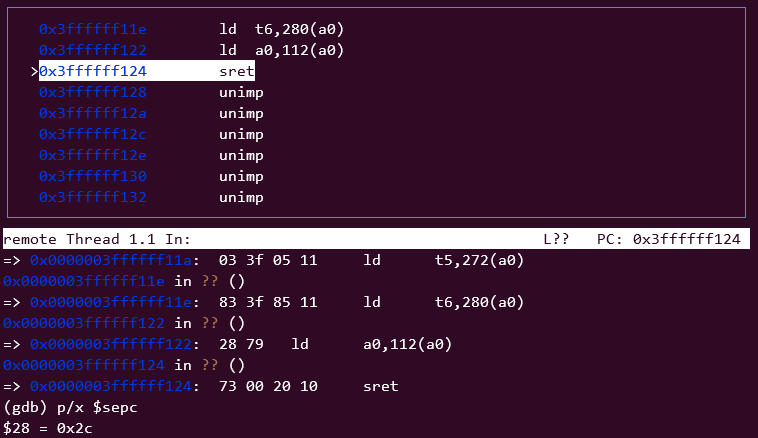
可以看到sepc保存的值是0x2c,返回到用户进程继续执行。